CISO Training Data Brief
This brief is meant to help CISOs understand the security challenges around Training Data and how Diffgram can help.
As a CISO (Chief Information Security Officer) you have a lot of responsibilities. Security, evolving cyber threats, data loss, ransomware, threat landscape, APTs, compliance, the list goes on…
One new area you may be tracking is that of Training Data, also called annotated data or labeled data.



Training data includes both raw data and human insights on that data.
Common CISO concerns around this data include:
- Exposure of raw data (such as images, videos, text, and other multimedia artifacts)
- Data Access — annotators, sometimes in foreign countries, contractors, data scientists
- Data Movement — is exported data lying around on peoples local machines? Are there unmanaged copies of the data?

- High value data controls: “completed” or “high value” training data sets — think crown jewels
- Threat landscape — as a new area the threat landscape is poorly defined and evolving
- APTs (Advanced Persistent Threats)
- Red/Blue/Purple team tests
- DevSecOps — Let’s call it DevSecMLOps… Yep MLOps needs security too!
- Dependency chains and Software Bill of Materials
- Ransomware — what would happen if your training data was maliciously encrypted or inaccessible?
In this article I’d like to touch on a few things to be aware of and how Diffgram can help.
Raw Data
One of the first big challenges is the raw data. This is especially challenging because there may be hard compliance requirements or contractual items around this data.
The good news is there are two simple paths that can alleviate a lot of these concerns nearly automatically. Both lean on your existing setup and help prevent unneeded complications.

Pass by Reference method
The super short story here is that the data doesn’t move. The Training Data platform (e.g. Diffgram) copies only a reference to the data, for example the blob path, and does not move the data. This means all of your existing compliance controls remain.
Without going into the weeds there are a variety of implementation options including a custom signer, so your own service can control access at the most granular levels.
Dedicated Storage method
Another method with Diffgram is you can configure your own new, dedicated, storage provider.
This could be as simple as a new bucket, or as complex as a dedicated MinIO cluster. In this case the data will be copied to this bucket, and new controls etc will need to be setup.
In both cases you have complete access control. There’s a variety of trade offs between these methods that our team is happy to engage with you on to meet your exact security needs.
Data Movement
Another big challenge is that of datasets “lying around” on people’s local machines. Even people with the best of intentions can create unnecessary security risks by doing this.

So why do they do it? Well the big challenge is that most legacy situations make it really hard to avoid this. In fact they may even encourage this, due to assumptions around what the end point is for the training datasets.
Of course the moment that a local copy of the entire dataset, and/or signed links to raw files, is made, a major portion of the security apparatus is invalidated.
So how do we prevent this?
One Set of Controls
By using Diffgram Training Data software your Data Scientists will be creating a unified schema, a unified view of the meaning of the data within your installation of Diffgram.
Annotators also complete the work inside your installation of Diffgram. There is no specific “Export” of the work at this stage.
All of the viewing of the data is handled by the access controls configured as part of the platform and identify providers (e.g. through an OIDC implementation).
This may sound somewhat simple, but in many cases we have seen valuable raw data made accessible directly to 3rd parties.
And we have seen in-progress reviews, and completed work being returned as one off file transfers. By keeping all the work inside your Diffgram platform a known security posture is maintained without further effort.
Catalog Over File Exports
The default in most other systems is to have a “File” level export. This usually means a file ends up on a data scientists local computer.
This is needed by Data Scientist's in order to query, sort and filter the data to a useful set, that’s step one. Step two for the data scientists is to load that data into their ML program of choice.
What if we could prevent that? What if you could maintain your security posture AND give a better experience to your data science team at the same time?
That’s where Diffgram Catalog comes in.
The Data Scientists first Query the data directly in your Diffgram installation. Again this means all your security controls are maintained, and it saves them having to download it. Win win.
Then when they arrive at step two, using the data in their ML program, instead of exporting to a static file, they Stream the data.
Catalog (Query and Stream) > Files lying around.


This allows use of “system level” tokens, in some cases the Data Scientists local machine may never even see the data, as only the ML program itself directly receives the data from the diffgram platform.
And even in cases where it does go to their local machine, it’s ephemeral, directly to their programs memory, there is no persistent file.
By using streaming you maintain a stronger security posture, and provide a better experience, with no extra effort on your part.
Installation and Integrations
Let’s face it. The best security is the security you control. Diffgram installs on your own hardware, your own cluster.
This gives you complete control over the security posture. Because Diffgram is open source, you can inspect all of the dependencies.
You don’t have to rely on us to identify the next log4j (we don’t use Java but still…). People all over the world are inspecting Diffgram code, the results of dependency scans etc. It’s important to remember Diffgram is the only fully open source option.
DevSecMLOps meet Workflow
The development of ML models introduces many challenges for maintaining the security of data.

As a Data Scientists there are an increasing number of valid use cases for making the data accessible to ML programs (e.g. filtering, sampling, similarity, etc).
This means that in the overall ops chains there are more steps. Think of this as an extended version of the file/streaming problem we mentioned earlier. How can you maintain security controls throughout this mess of black boxes?
Diffgram Workflow is the bridge between ML/Dev Ops, and the Training Data.
Workflow surfaces the relationships and data flow between between ML programs, end-user apps, and Training Data.
You can think of it as a set of standards for Training Data integrations, solving many of the security challenges at the same time.
For example, data flows directly between apps (sometimes running directly on the diffgram installation) instead of local file copies or hidden one off scripts.
Workflow turns an unknown number of ML black boxes into clear processes visible to all (…with access 😉).
There are even provisions for capturing the output of models, for example for production data. That means you can secure the entire processes, end to end, from model dev through production and back again.
All of this was built with the Data Scientists in mind. Diffgram Workflow integrations save time for Data Scientists too, another great win win. Data Scientists get an easier time doing what they want to do, and you increase security at the same time. As long as it’s using Diffgram Workflow you know the security controls you have set are being maintained.
Ransomware
At the time of writing, other options like LabelBox, don’t have a published ransomware plan.
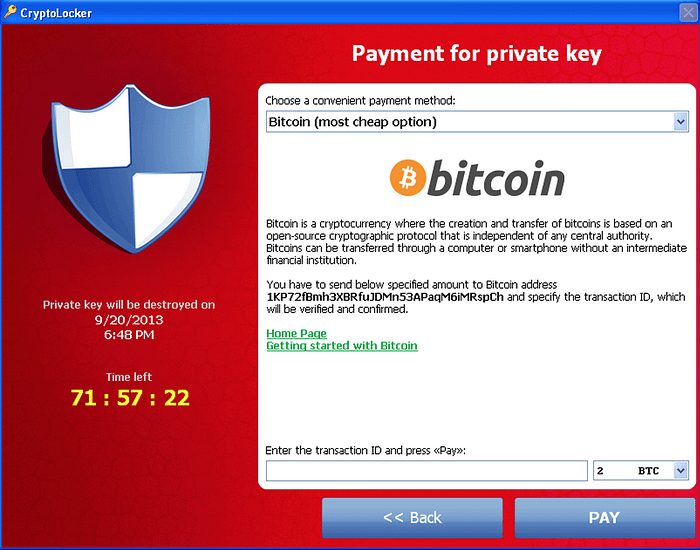
What would happen if they were hit with a ransomware attack? Would your data be safe?
As we know the smaller the attack surface the better. Diffgram installs on your own network. In many cases this may mean it’s not even accessible to inbound public IP traffic. In other words, how would an attacker ransom what they don’t know exists?
Of course there’s always risks, but this allows your global policies and controls to apply equally well to your training data. No reliance on a 3rd parties controls. Further with Diffgram you can use actions to create automatic back-ups and restore plans. So even in the unlikely event that the the installation is somehow discovered, and your controls breached, you can continue business operations.
Thanks for reading!
There are many other security challenges and considerations we can discuss. If you are an enterprise looking for your first training data platform, or to switch to Diffgram, contact us today.
